Note: A new GRASS GIS stable version has been released: GRASS GIS 7.8, available here.
Updated manual page: here
NAME
i.cluster - Generates spectral signatures for land cover types in an image using a clustering algorithm.The resulting signature file is used as input for i.maxlik, to generate an unsupervised image classification.
KEYWORDS
imagery, classification, signaturesSYNOPSIS
Flags:
- --overwrite
- Allow output files to overwrite existing files
- --help
- Print usage summary
- --verbose
- Verbose module output
- --quiet
- Quiet module output
- --ui
- Force launching GUI dialog
Parameters:
- group=name [required]
- Name of input imagery group
- subgroup=name [required]
- Name of input imagery subgroup
- signaturefile=name [required]
- Name for output file containing result signatures
- classes=integer [required]
- Initial number of classes
- Options: 1-255
- seed=name
- Name of file containing initial signatures
- sample=row_interval,col_interval
- Sampling intervals (by row and col); default: ~10,000 pixels
- iterations=integer
- Maximum number of iterations
- Default: 30
- convergence=float
- Percent convergence
- Options: 0-100
- Default: 98.0
- separation=float
- Cluster separation
- Default: 0.0
- min_size=integer
- Minimum number of pixels in a class
- Default: 17
- reportfile=name
- Name for output file containing final report
Table of contents
DESCRIPTION
i.cluster performs the first pass in the two-pass unsupervised classification of imagery, while the GRASS module i.maxlik executes the second pass. Both commands must be run to complete the unsupervised classification.i.cluster is a clustering algorithm (a modification of the k-means clustering algorithm) that reads through the (raster) imagery data and builds pixel clusters based on the spectral reflectances of the pixels (see Figure). The pixel clusters are imagery categories that can be related to land cover types on the ground. The spectral distributions of the clusters (e.g., land cover spectral signatures) are influenced by six parameters set by the user. A relevant parameter set by the user is the initial number of clusters to be discriminated.
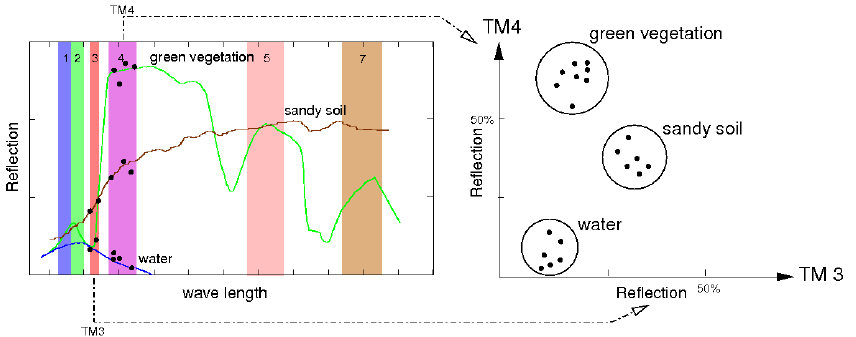
i.cluster starts by generating spectral signatures for this number of clusters and "attempts" to end up with this number of clusters during the clustering process. The resulting number of clusters and their spectral distributions, however, are also influenced by the range of the spectral values (category values) in the image files and the other parameters set by the user. These parameters are: the minimum cluster size, minimum cluster separation, the percent convergence, the maximum number of iterations, and the row and column sampling intervals.
The cluster spectral signatures that result are composed of cluster means and covariance matrices. These cluster means and covariance matrices are used in the second pass (i.maxlik) to classify the image. The clusters or spectral classes result can be related to land cover types on the ground. The user has to specify the name of group file, the name of subgroup file, the name of a file to contain result signatures, the initial number of clusters to be discriminated, and optionally other parameters (see below) where the group should contain the imagery files that the user wishes to classify. The subgroup is a subset of this group. The user must create a group and subgroup by running the GRASS program i.group before running i.cluster. The subgroup should contain only the imagery band files that the user wishes to classify. Note that this subgroup must contain more than one band file. The purpose of the group and subgroup is to collect map layers for classification or analysis. The signaturefile is the file to contain result signatures which can be used as input for i.maxlik. The classes value is the initial number of clusters to be discriminated; any parameter values left unspecified are set to their default values.
Parameters:
- group=name
- The name of the group file which contains the imagery files that the user wishes to classify.
- subgroup=name
- The name of the subset of the group specified in group option, which must contain only imagery band files and more than one band file. The user must create a group and a subgroup by running the GRASS program i.group before running i.cluster.
- signaturefile=name
- The name assigned to output signature file which contains signatures of classes and can be used as the input file for the GRASS program i.maxlik for an unsupervised classification.
- classes=value
- The number of clusters that will initially be identified in the clustering process before the iterations begin.
- seed=name
- The name of a seed signature file is optional. The seed signatures are signatures that contain cluster means and covariance matrices which were calculated prior to the current run of i.cluster. They may be acquired from a previously run of i.cluster or from a supervised classification signature training site section (e.g., using the signature file output by g.gui.iclass). The purpose of seed signatures is to optimize the cluster decision boundaries (means) for the number of clusters specified.
- sample=row_interval,col_interval
- These numbers are optional with default values based on the size of the data set such that the total pixels to be processed is approximately 10,000 (consider round up).
- iterations=value
- This parameter determines the maximum number of
iterations which is greater than the number of iterations
predicted to achieve the optimum percent convergence. The
default value is 30. If the number of iterations reaches
the maximum designated by the user; the user may want to
rerun i.cluster with a higher number of iterations
(see reportfile).
Default: 30 - convergence=value
- A high percent convergence is the point at which
cluster means become stable during the iteration process.
The default value is 98.0 percent. When clusters are being
created, their means constantly change as pixels are
assigned to them and the means are recalculated to include
the new pixel. After all clusters have been created,
i.cluster begins iterations that change cluster
means by maximizing the distances between them. As these
means shift, a higher and higher convergence is
approached. Because means will never become totally
static, a percent convergence and a maximum number of
iterations are supplied to stop the iterative process. The
percent convergence should be reached before the maximum
number of iterations. If the maximum number of iterations
is reached, it is probable that the desired percent
convergence was not reached. The number of iterations is
reported in the cluster statistics in the report file
(see reportfile).
Default: 98.0 - separation=value
- This is the minimum separation below which clusters
will be merged in the iteration process. The default value
is 0.0. This is an image-specific number (a "magic" number)
that depends on the image data being classified and the
number of final clusters that are acceptable. Its
determination requires experimentation. Note that as the
minimum class (or cluster) separation is increased, the
maximum number of iterations should also be increased to
achieve this separation with a high percentage of
convergence
(see convergence).
Default: 0.0 - min_size=value
- This is the minimum number of pixels that will be used
to define a cluster, and is therefore the minimum number of
pixels for which means and covariance matrices will be
calculated.
Default: 17 - reportfile=name
- The reportfile is an optional parameter which contains the result, i.e., the statistics for each cluster. Also included are the resulting percent convergence for the clusters, the number of iterations that was required to achieve the convergence, and the separability matrix.
NOTES
Sampling method
i.cluster does not cluster all pixels, but only a sample (see parameter sample). The result of that clustering is not that all pixels are assigned to a given cluster; essentially, only signatures which are representative of a given cluster are generated. When running i.cluster on the same data asking for the same number of classes, but with different sample sizes, likely slightly different signatures for each cluster are obtained at each run.Algorithm used for i.cluster
The algorithm uses input parameters set by the user on the initial number of clusters, the minimum distance between clusters, and the correspondence between iterations which is desired, and minimum size for each cluster. It also asks if all pixels to be clustered, or every "x"th row and "y"th column (sampling), the correspondence between iterations desired, and the maximum number of iterations to be carried out.In the 1st pass, initial cluster means for each band are defined by giving the first cluster a value equal to the band mean minus its standard deviation, and the last cluster a value equal to the band mean plus its standard deviation, with all other cluster means distributed equally spaced in between these. Each pixel is then assigned to the class which it is closest to, distance being measured as Euclidean distance. All clusters less than the user-specified minimum distance are then merged. If a cluster has less than the user-specified minimum number of pixels, all those pixels are again reassigned to the next nearest cluster. New cluster means are calculated for each band as the average of raster pixel values in that band for all pixels present in that cluster.
In the 2nd pass, pixels are then again reassigned to clusters based on new cluster means. The cluster means are then again recalculated. This process is repeated until the correspondence between iterations reaches a user-specified level, or till the maximum number of iterations specified is over, whichever comes first.
EXAMPLE
Preparing the statistics for unsupervised classification of a LANDSAT subscene in North Carolina:g.region raster=lsat7_2002_10 -p # store VIZ, NIR, MIR into group/subgroup (leaving out TIR) i.group group=lsat7_2002 subgroup=lsat7_2002 \ input=lsat7_2002_10,lsat7_2002_20,lsat7_2002_30,lsat7_2002_40,lsat7_2002_50,lsat7_2002_70 # generate signature file and report i.cluster group=lsat7_2002 subgroup=lsat7_2002 \ signaturefile=sig_cluster_lsat2002 \ classes=10 reportfile=rep_clust_lsat2002.txt
SEE ALSO
- Image classification wiki page
- Historical reference also the GRASS GIS 4 Image Processing manual (PDF)
- Wikipedia article on k-means clustering (note that i.cluster uses a modification of the k-means clustering algorithm)
g.gui.iclass, i.group, i.gensig, i.maxlik, i.segment, i.smap, r.kappa
AUTHORS
Michael Shapiro, U.S. Army Construction Engineering Research LaboratoryTao Wen, University of Illinois at Urbana-Champaign, Illinois
Last changed: $Date$
SOURCE CODE
Available at: i.cluster source code (history)
Note: A new GRASS GIS stable version has been released: GRASS GIS 7.8, available here.
Updated manual page: here
Main index | Imagery index | Topics index | Keywords index | Graphical index | Full index
© 2003-2020 GRASS Development Team, GRASS GIS 7.6.2dev Reference Manual