NAME
v.dissolve - Dissolves adjacent or overlapping features sharing a common category number or attribute.KEYWORDS
vector, dissolve, area, lineSYNOPSIS
Flags:
- --overwrite
- Allow output files to overwrite existing files
- --help
- Print usage summary
- --verbose
- Verbose module output
- --quiet
- Quiet module output
- --ui
- Force launching GUI dialog
Parameters:
- input=name [required]
- Name of input vector map
- Or data source for direct OGR access
- layer=string
- Layer number or name.
- Vector features can have category values in different layers. This number determines which layer to use. When used with direct OGR access this is the layer name.
- Default: 1
- column=name
- Name of attribute column used to dissolve features
- output=name [required]
- Name for output vector map
- aggregate_columns=name[,name,...]
- Names of attribute columns to get aggregate statistics for
- One column name or SQL expression per method if result columns are specified
- aggregate_methods=string[,string,...]
- Aggregate statistics method (e.g., sum)
- Default is all available basic statistics for a given backend (for sql backend: avg, count, max, min, sum)
- result_columns=name[,name,...]
- New attribute column names for aggregate statistics results
- Defaults to aggregate column name and statistics name and can contain type
- aggregate_backend=string
- Backend for attribute aggregation
- Default is sql unless the provided aggregate methods are for univar
- Options: sql, univar
- sql: Uses SQL attribute database
- univar: Uses v.db.univar
Table of contents
DESCRIPTION
The v.dissolve module is used to merge adjacent or overlapping features in a vector map that share the same category value. The resulting merged feature(s) retain this category value.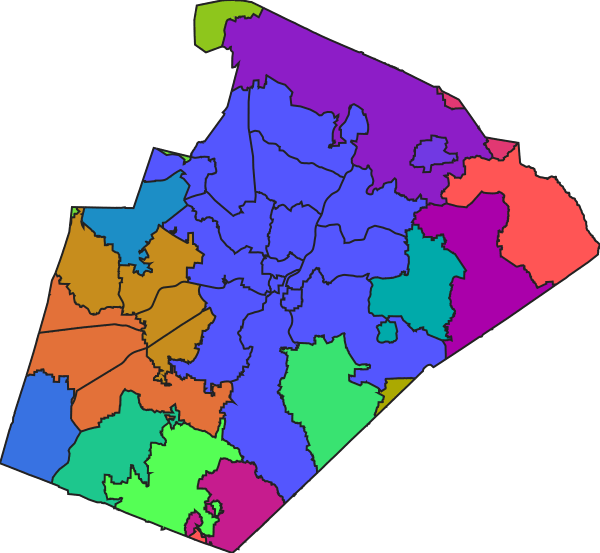
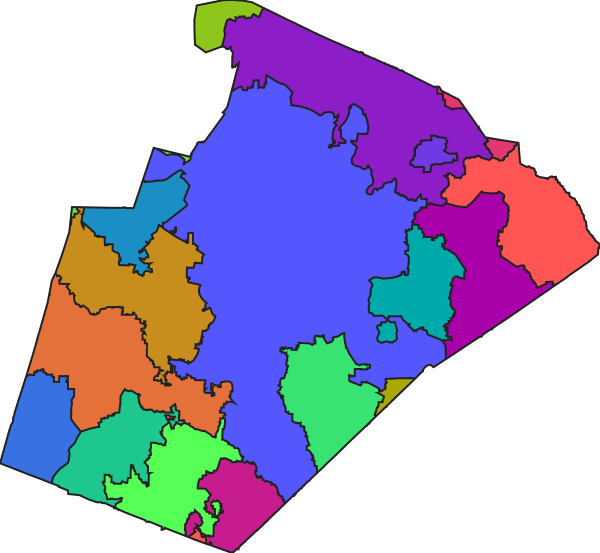
Figure: Areas with the same attribute value (first image) are merged into one (second image).
Instead of dissolving features based on the category values, the user can define an integer or string column using the column parameter. In that case, features that share the same value in that column are dissolved. Note, the newly created layer does not retain the category (cat) values from the input layer.
Note that multiple areas with the same category or the same attribute value that are not adjacent are merged into one entity, which consists of multiple features, i.e., a multipart feature.
Attribute aggregation
The attributes of merged areas can be aggregated using various aggregation methods. The specific methods available depend on the backend used for aggregation. Two aggregate backends (specified with the aggregate_backend parameter) are available, univar and sql. The backend is determined automatically based on the requested methods. When the function is one of the SQL build-in aggregate functions, the sql backend is used. Otherwise, the univar backend is used.The default behavior is intended for interactive use and testing. For scripting and other automated usage, explicitly specifying the backend with the aggregate_backend parameter is strongly recommended. When choosing, note that the sql aggregate backend, regardless of the underlying database, will typically perform significantly better than the univar backend.
Aggregation using univar backend
When univar is used, the methods available are the ones which v.db.univar uses by default, i.e., n, min, max, range, mean, mean_abs, variance, stddev, coef_var, and sum.Aggregation using sql backend
When the sql backend is used, the methods depend on the SQL database backend used for the attribute table of the input vector. For SQLite, there are at least the following built-in aggregate functions: count, min, max, avg, sum, and total. For PostgreSQL, the list of aggregate functions is much longer and includes, e.g., count, min, max, avg, sum, stddev, and variance.Defining the aggregation method
If only the parameter aggregate_columns is provided, all the following aggregation statistics are calculated: n, min, max, mean, and sum. If the univar backend is specified, all the available methods for the univar backend are used.The aggregate_methods parameter can be used to specify which aggregation statistics should be computed. Alternatively, the parameter aggregate_columns can be used to specify the method using SQL syntax. This provides the highest flexibility, and it is suitable for scripting. The SQL statement should specify both the column and the functions applied, e.g.,
aggregate_columns="sum(cows) / sum(animals)".
Note that when the aggregate_columns parameter is used, the sql backend should be used. In addition, the aggregate_columns and aggregate_methods cannot be used together.
For convenience, certain methods, namely n, count, mean, and avg, are automatically converted to the appropriate name for the selected backend. However, for scripting, it is recommended to specify the appropriate method (function) name for the backend, as the conversion is a heuristic that may change in the future.
If the result_columns is not provided, each method is applied to each column specified by aggregate_columns. This results in a column for each of the combinations. These result columns have auto-generated names based on the aggregate column and method. For example, setting the following parameters:
aggregate_columns=A,B aggregate_methods=sum,n
results in the following columns: A_sum, A_n, B_sum, B_n. See the Examples section.
If the result_column is provided, each method is applied only once to the matching column in the aggregate column list, and the result will be available under the name of the matching result column. For example, setting the following parameter:
aggregate_columns=A,B aggregate_methods=sum,max result_column=sum_a, n_b
results in the column sum_a with the sum of the values of A and the column n_b with the max of B. Note that the number of items in aggregate_columns, aggregate_methods (unless omitted), and result_column needs to match, and no combinations are created on the fly. See the Examples section.
For scripting, it is recommended to specify all resulting column names, while for interactive use, automatically created combinations are expected to be beneficial, especially for exploratory analysis.
The type of the result column is determined based on the method
selected. For n and count, the type is INTEGER and
for all other methods, it is DOUBLE. Aggregate methods that produce
other types require the type to be specified as part of the
result_columns. A type can be provided in result_columns
using the SQL syntax name type, e.g., sum_of_values
double precision. Type specification is mandatory when SQL
syntax is used in aggregate_columns (and
aggregate_methods is omitted).
NOTES
GRASS defines a vector area as a composite entity consisting of a set of closed boundaries and a centroid. The centroids must contain a category number (see v.centroids), this number is linked to area attributes and database links.Multiple attributes may be linked to a single vector entity through numbered fields referred to as layers. Refer to v.category for more details.
Merging of areas can also be accomplished using v.extract -d
which provides some additional options. In fact, v.dissolve is
simply a front-end to that module. The use of the column
parameter adds a call to v.reclass before.
EXAMPLES
Basic use
v.dissolve input=undissolved output=dissolved
Dissolving based on column attributes
North Carolina data set:g.copy vect=soils_general,mysoils_general v.dissolve mysoils_general output=mysoils_general_families column=GSL_NAME
Dissolving adjacent SHAPE files to remove tile boundaries
If tile boundaries of adjacent maps (e.g. CORINE Landcover SHAPE files) have to be removed, an extra step is required to remove duplicated boundaries:# patch tiles after import: v.patch -e `g.list type=vector pat="clc2000_*" separator=","` out=clc2000_patched # remove duplicated tile boundaries: v.clean clc2000_patched out=clc2000_clean tool=snap,break,rmdupl thresh=.01 # dissolve based on column attributes: v.dissolve input=clc2000_clean output=clc2000_final col=CODE_00
Attribute aggregation
While dissolving, we can aggregate attribute values of the original features. Let's aggregate area in acres (ACRES) of all municipal boundaries (boundary_municp) in the full NC dataset while dissolving common boundaries based on the name in the DOTURBAN_N column (long lines are split with backslash marking continued line as in Bash):
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities \
aggregate_columns=ACRES
To inspect the result, we will use v.db.select retrieving only one row
for DOTURBAN_N == 'Wadesboro':
v.db.select municipalities where="DOTURBAN_N == 'Wadesboro'" separator=tab
The resulting table may look like this:
cat DOTURBAN_N ACRES_n ACRES_min ACRES_max ACRES_mean ACRES_sum 66 Wadesboro 2 634.987 3935.325 2285.156 4570.312
The above created multiple columns for each of the statistics computed by default. We can limit the number of statistics computed by specifying the method which should be used:
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities_2 \
aggregate_columns=ACRES aggregate_methods=sum
The above gives a single column with the sum for all values in the ACRES column for each group of original features which had the same value in the DOTURBAN_N column and are now dissolved (merged) into one.
Aggregating multiple attributes
Expanding on the previous example, we can compute values for multiple columns at once by adding more columns to the aggregate_columns option. We will compute average of values in the NEW_PERC_G column:
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities_3 \
aggregate_columns=ACRES,NEW_PERC_G aggregate_methods=sum,avg
By default, all methods specified in the aggregate_methods are applied to all columns, so result of the above is four columns. While this is convenient for getting multiple statistics for similar columns (e.g. averages and standard deviations of multiple population statistics columns), in our case, each column is different and each aggregate method should be applied only to its corresponding column.
The v.dissolve module will apply each aggregate method only to the corresponding column when column names for the results are specified manually with the result_columns option:
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities_4 \
aggregate_columns=ACRES,NEW_PERC_G aggregate_methods=sum,avg \
result_columns=acres,new_perc_g
Now we have full control over what columns are created, but we also need to specify an aggregate method for each column even when the aggregate methods are the same:
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities_5 \
aggregate_columns=ACRES,DOTURBAN_N,TEXT_NAME aggregate_methods=sum,count,count \
result_columns=acres,number_of_parts,named_parts
While it is often not necessary to specify aggregate methods or names for interactive exploratory analysis, specifying both aggregate_methods and result_columns manually is a best practice for scripting (unless SQL syntax is used for aggregate_columns, see below).
Aggregating using SQL syntax
The aggregation can be done also using the full SQL syntax and set of aggregate functions available for a given attribute database backend. Here, we will assume the default SQLite database backend for attribute.
Modifying the previous example, we will now specify the SQL aggregate
function calls explicitly instead of letting v.dissolve
generate them for us. We will compute sum of the ACRES column using
sum(ACRES) (alternatively, we could use SQLite specific
total(ACRES) which returns zero even when all values are
NULL). Further, we will count number of aggregated (i.e., dissolved)
parts using count(*) which counts all rows regardless of
NULL values. Then, we will count all unique names of parts as
distinguished by the MB_NAME column using count(distinct
MB_NAME). Finally, we will collect all these names into a
comma-separated list using group_concat(MB_NAME):
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities_6 \
aggregate_columns="total(ACRES),count(*),count(distinct MB_NAME),group_concat(MB_NAME)" \
result_columns="acres REAL,named_parts INTEGER,unique_names INTEGER,names TEXT"
Here, v.dissolve doesn't make any assumptions about the resulting column types, so we specified both named and the type of each column.
When working with general SQL syntax, v.dissolve turns off its checks for number of aggregate and result columns to allow for all SQL syntax to be used for aggregate columns. This allows us to use also functions with multiple parameters, for example specify separator to be used with group_concat:
v.dissolve input=boundary_municp column=DOTURBAN_N output=municipalities_7 \
aggregate_columns="group_concat(MB_NAME, ';')" \
result_columns="names TEXT"
To inspect the result, we will use v.db.select retrieving only
one row for DOTURBAN_N == 'Wadesboro':
v.db.select municipalities_7 where="DOTURBAN_N == 'Wadesboro'" separator=tab
The resulting table may look like this:
cat DOTURBAN_N names 66 Wadesboro Wadesboro;Lilesville
SEE ALSO
v.category, v.centroids, v.extract, v.reclass, v.db.univar, v.db.selectAUTHORS
M. Hamish Bowman, Department of Marine Science, Otago University, New Zealand (module)Markus Neteler (column support)
Trevor Wiens (help page)
Vaclav Petras, NC State University, Center for Geospatial Analytics, GeoForAll Lab (aggregate statistics)
SOURCE CODE
Available at: v.dissolve source code (history)
Latest change: Saturday Oct 11 04:38:40 2025 in commit: 3dd71f5fab83b72a2db2da959fe075c5b3b52200
Main index | Vector index | Topics index | Keywords index | Graphical index | Full index
© 2003-2026 GRASS Development Team, GRASS 8.5.1dev Reference Manual