r.learn.ml
Supervised classification and regression of GRASS rasters using the python scikit-learn package
r.learn.ml [-tfrspzmbl] group=name [trainingmap=name] [trainingpoints=name] [field=name] [output=name] [classifier=string] [c=float [,float,...]] [max_features=integer [,integer,...]] [max_depth=integer [,integer,...]] [min_samples_split=integer [,integer,...]] [min_samples_leaf=integer [,integer,...]] [n_estimators=integer [,integer,...]] [learning_rate=float [,float,...]] [subsample=float [,float,...]] [max_degree=integer [,integer,...]] [n_neighbors=integer [,integer,...]] [weights=string [,string,...]] [grid_search=string] [categorymaps=name [,name,...]] [cvtype=string] [n_partitions=integer] [group_raster=name] [cv=integer] [n_permutations=integer] [errors_file=name] [preds_file=name] [fimp_file=name] [param_file=name] [random_state=integer] [indexes=integer [,integer,...]] [rowincr=integer] [n_jobs=integer] [save_training=name] [load_training=name] [save_model=name] [load_model=name] [--overwrite] [--verbose] [--quiet] [--qq] [--ui]
Example:
r.learn.ml group=name
grass.tools.Tools.r_learn_ml(group, trainingmap=None, trainingpoints=None, field=None, output=None, classifier="RandomForestClassifier", c=1.0, max_features=0, max_depth=0, min_samples_split=2, min_samples_leaf=1, n_estimators=100, learning_rate=0.1, subsample=1.0, max_degree=1, n_neighbors=5, weights="uniform", grid_search="cross-validation", categorymaps=None, cvtype="Non-spatial", n_partitions=10, group_raster=None, cv=1, n_permutations=10, errors_file=None, preds_file=None, fimp_file=None, param_file=None, random_state=1, indexes=-1, rowincr=25, n_jobs=-2, save_training=None, load_training=None, save_model=None, load_model=None, flags=None, overwrite=None, verbose=None, quiet=None, superquiet=None)
Example:
tools = Tools()
tools.r_learn_ml(group="name")
This grass.tools API is experimental in version 8.5 and expected to be stable in version 8.6.
grass.script.run_command("r.learn.ml", group, trainingmap=None, trainingpoints=None, field=None, output=None, classifier="RandomForestClassifier", c=1.0, max_features=0, max_depth=0, min_samples_split=2, min_samples_leaf=1, n_estimators=100, learning_rate=0.1, subsample=1.0, max_degree=1, n_neighbors=5, weights="uniform", grid_search="cross-validation", categorymaps=None, cvtype="Non-spatial", n_partitions=10, group_raster=None, cv=1, n_permutations=10, errors_file=None, preds_file=None, fimp_file=None, param_file=None, random_state=1, indexes=-1, rowincr=25, n_jobs=-2, save_training=None, load_training=None, save_model=None, load_model=None, flags=None, overwrite=None, verbose=None, quiet=None, superquiet=None)
Example:
gs.run_command("r.learn.ml", group="name")
Parameters
group=name [required]
Group of raster layers to be classified
GRASS imagery group of raster maps representing feature variables to be used in the machine learning model
trainingmap=name
Labelled pixels
Raster map with labelled pixels for training
trainingpoints=name
Vector map with training samples
Vector points map where each point is used as training sample. Handling of missing values in training data can be choosen later.
field=name
Response attribute column
Name of attribute column in trainingpoints table containing response values
output=name
Output Map
Raster layer name to store result from classification or regression model. The name will also used as a perfix if class probabilities or intermediate of cross-validation results are ordered as maps.
classifier=string
Classifier
Supervised learning model to use
Allowed values: LogisticRegression, LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis, KNeighborsClassifier, GaussianNB, DecisionTreeClassifier, DecisionTreeRegressor, RandomForestClassifier, RandomForestRegressor, ExtraTreesClassifier, ExtraTreesRegressor, GradientBoostingClassifier, GradientBoostingRegressor, SVC, EarthClassifier, EarthRegressor
Default: RandomForestClassifier
c=float [,float,...]
Inverse of regularization strength
Inverse of regularization strength (LogisticRegression and SVC)
Default: 1.0
max_features=integer [,integer,...]
Number of features available during node splitting; zero uses classifier defaults
Number of features available during node splitting (tree-based classifiers and regressors)
Default: 0
max_depth=integer [,integer,...]
Maximum tree depth; zero uses classifier defaults
Maximum tree depth for tree-based method; zero uses classifier defaults (full-growing for Decision trees and Randomforest, 3 for GBM)
Default: 0
min_samples_split=integer [,integer,...]
The minimum number of samples required for node splitting
The minimum number of samples required for node splitting in tree-based classifiers
Default: 2
min_samples_leaf=integer [,integer,...]
The minimum number of samples required to form a leaf node
The minimum number of samples required to form a leaf node in tree-based classifiers
Default: 1
n_estimators=integer [,integer,...]
Number of estimators
Number of estimators (trees) in ensemble tree-based classifiers
Default: 100
learning_rate=float [,float,...]
learning rate
learning rate (also known as shrinkage) for gradient boosting methods
Default: 0.1
subsample=float [,float,...]
The fraction of samples to be used for fitting
The fraction of samples to be used for fitting, controls stochastic behaviour of gradient boosting methods
Default: 1.0
max_degree=integer [,integer,...]
The maximum degree of terms in forward pass
The maximum degree of terms in forward pass for Py-earth
Default: 1
n_neighbors=integer [,integer,...]
Number of neighbors to use
Number of neighbors to use
Default: 5
weights=string [,string,...]
weight function
Distance weight function for k-nearest neighbours model prediction
Allowed values: uniform, distance
Default: uniform
grid_search=string
Resampling method to use for hyperparameter optimization
Resampling method to use for hyperparameter optimization
Allowed values: cross-validation, holdout
Default: cross-validation
categorymaps=name [,name,...]
Names of categorical rasters within the imagery group
Names of categorical rasters within the imagery group that will be one-hot encoded. Leave empty if none.
cvtype=string
Non-spatial or spatial cross-validation
Perform non-spatial, clumped or clustered k-fold cross-validation
Allowed values: non-spatial, clumped, kmeans
Default: Non-spatial
n_partitions=integer
Number of k-means spatial partitions
Number of k-means spatial partitions for k-means clustered cross-validation
Default: 10
group_raster=name
Custom group ids for training samples from GRASS raster
GRASS raster containing group ids for training samples. Samples with the same group id will not be split between training and test cross-validation folds
cv=integer
Number of cross-validation folds
Default: 1
n_permutations=integer
Number of permutations to perform for feature importances
Default: 10
errors_file=name
Save cross-validation global accuracy results to csv
Name for output file
preds_file=name
Save cross-validation predictions to csv
Name for output file
fimp_file=name
Save feature importances to csv
Name for output file
param_file=name
Save hyperparameter search scores to csv
Name for output file
random_state=integer
Seed to use for random state
Default: 1
indexes=integer [,integer,...]
Indexes of class probabilities to predict. Default -1 predicts all classes
Default: -1
rowincr=integer
Maximum number of raster rows to read/write in single chunk whilst performing prediction
Default: 25
n_jobs=integer
Number of cores for multiprocessing, -2 is n_cores-1
Default: -2
save_training=name
Save training data to csv
Name for output file
load_training=name
Load training data from csv
Name of input file
save_model=name
Save model to file (for compression use e.g. '.gz' extension)
Name for output file
load_model=name
Load model from file
Name of input file
-t
Perform hyperparameter tuning only
-f
Estimate permutation-based feature importances
Estimate feature importance using a permutation-based method
-r
Make predictions for cross validation resamples
Produce raster predictions for all cross validation resamples
-s
Standardization preprocessing
Standardize feature variables (convert values the get zero mean and unit variance).
-p
Output class membership probabilities
A raster layer is created for each class. It is recommended to give a list of particular classes in interest to avoid consumption of large amounts of disk space.
-z
Only predict class probabilities
-m
Build model only - do not perform prediction
-b
Balance training data using class weights
-l
Use memory swap
--overwrite
Allow output files to overwrite existing files
--help
Print usage summary
--verbose
Verbose module output
--quiet
Quiet module output
--qq
Very quiet module output
--ui
Force launching GUI dialog
group : str, required
Group of raster layers to be classified
GRASS imagery group of raster maps representing feature variables to be used in the machine learning model
Used as: input, group, name
trainingmap : str | np.ndarray, optional
Labelled pixels
Raster map with labelled pixels for training
Used as: input, raster, name
trainingpoints : str, optional
Vector map with training samples
Vector points map where each point is used as training sample. Handling of missing values in training data can be choosen later.
Used as: input, vector, name
field : str, optional
Response attribute column
Name of attribute column in trainingpoints table containing response values
Used as: input, dbcolumn, name
output : str | type(np.ndarray) | type(np.array) | type(gs.array.array), optional
Output Map
Raster layer name to store result from classification or regression model. The name will also used as a perfix if class probabilities or intermediate of cross-validation results are ordered as maps.
Used as: output, raster, name
classifier : str, optional
Classifier
Supervised learning model to use
Allowed values: LogisticRegression, LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis, KNeighborsClassifier, GaussianNB, DecisionTreeClassifier, DecisionTreeRegressor, RandomForestClassifier, RandomForestRegressor, ExtraTreesClassifier, ExtraTreesRegressor, GradientBoostingClassifier, GradientBoostingRegressor, SVC, EarthClassifier, EarthRegressor
Default: RandomForestClassifier
c : float | list[float] | str, optional
Inverse of regularization strength
Inverse of regularization strength (LogisticRegression and SVC)
Default: 1.0
max_features : int | list[int] | str, optional
Number of features available during node splitting; zero uses classifier defaults
Number of features available during node splitting (tree-based classifiers and regressors)
Default: 0
max_depth : int | list[int] | str, optional
Maximum tree depth; zero uses classifier defaults
Maximum tree depth for tree-based method; zero uses classifier defaults (full-growing for Decision trees and Randomforest, 3 for GBM)
Default: 0
min_samples_split : int | list[int] | str, optional
The minimum number of samples required for node splitting
The minimum number of samples required for node splitting in tree-based classifiers
Default: 2
min_samples_leaf : int | list[int] | str, optional
The minimum number of samples required to form a leaf node
The minimum number of samples required to form a leaf node in tree-based classifiers
Default: 1
n_estimators : int | list[int] | str, optional
Number of estimators
Number of estimators (trees) in ensemble tree-based classifiers
Default: 100
learning_rate : float | list[float] | str, optional
learning rate
learning rate (also known as shrinkage) for gradient boosting methods
Default: 0.1
subsample : float | list[float] | str, optional
The fraction of samples to be used for fitting
The fraction of samples to be used for fitting, controls stochastic behaviour of gradient boosting methods
Default: 1.0
max_degree : int | list[int] | str, optional
The maximum degree of terms in forward pass
The maximum degree of terms in forward pass for Py-earth
Default: 1
n_neighbors : int | list[int] | str, optional
Number of neighbors to use
Number of neighbors to use
Default: 5
weights : str | list[str], optional
weight function
Distance weight function for k-nearest neighbours model prediction
Allowed values: uniform, distance
Default: uniform
grid_search : str, optional
Resampling method to use for hyperparameter optimization
Resampling method to use for hyperparameter optimization
Allowed values: cross-validation, holdout
Default: cross-validation
categorymaps : str | list[str], optional
Names of categorical rasters within the imagery group
Names of categorical rasters within the imagery group that will be one-hot encoded. Leave empty if none.
Used as: input, raster, name
cvtype : str, optional
Non-spatial or spatial cross-validation
Perform non-spatial, clumped or clustered k-fold cross-validation
Allowed values: non-spatial, clumped, kmeans
Default: Non-spatial
n_partitions : int, optional
Number of k-means spatial partitions
Number of k-means spatial partitions for k-means clustered cross-validation
Default: 10
group_raster : str | np.ndarray, optional
Custom group ids for training samples from GRASS raster
GRASS raster containing group ids for training samples. Samples with the same group id will not be split between training and test cross-validation folds
Used as: input, raster, name
cv : int, optional
Number of cross-validation folds
Default: 1
n_permutations : int, optional
Number of permutations to perform for feature importances
Default: 10
errors_file : str, optional
Save cross-validation global accuracy results to csv
Name for output file
Used as: output, file, name
preds_file : str, optional
Save cross-validation predictions to csv
Name for output file
Used as: output, file, name
fimp_file : str, optional
Save feature importances to csv
Name for output file
Used as: output, file, name
param_file : str, optional
Save hyperparameter search scores to csv
Name for output file
Used as: output, file, name
random_state : int, optional
Seed to use for random state
Default: 1
indexes : int | list[int] | str, optional
Indexes of class probabilities to predict. Default -1 predicts all classes
Default: -1
rowincr : int, optional
Maximum number of raster rows to read/write in single chunk whilst performing prediction
Default: 25
n_jobs : int, optional
Number of cores for multiprocessing, -2 is n_cores-1
Default: -2
save_training : str, optional
Save training data to csv
Name for output file
Used as: output, file, name
load_training : str | io.StringIO, optional
Load training data from csv
Name of input file
Used as: input, file, name
save_model : str, optional
Save model to file (for compression use e.g. '.gz' extension)
Name for output file
Used as: output, file, name
load_model : str | io.StringIO, optional
Load model from file
Name of input file
Used as: input, file, name
flags : str, optional
Allowed values: t, f, r, s, p, z, m, b, l
t
Perform hyperparameter tuning only
f
Estimate permutation-based feature importances
Estimate feature importance using a permutation-based method
r
Make predictions for cross validation resamples
Produce raster predictions for all cross validation resamples
s
Standardization preprocessing
Standardize feature variables (convert values the get zero mean and unit variance).
p
Output class membership probabilities
A raster layer is created for each class. It is recommended to give a list of particular classes in interest to avoid consumption of large amounts of disk space.
z
Only predict class probabilities
m
Build model only - do not perform prediction
b
Balance training data using class weights
l
Use memory swap
overwrite : bool, optional
Allow output files to overwrite existing files
Default: None
verbose : bool, optional
Verbose module output
Default: None
quiet : bool, optional
Quiet module output
Default: None
superquiet : bool, optional
Very quiet module output
Default: None
Returns:
result : grass.tools.support.ToolResult | np.ndarray | tuple[np.ndarray] | None
If the tool produces text as standard output, a ToolResult object will be returned. Otherwise, None will be returned. If an array type (e.g., np.ndarray) is used for one of the raster outputs, the result will be an array and will have the shape corresponding to the computational region. If an array type is used for more than one raster output, the result will be a tuple of arrays.
Raises:
grass.tools.ToolError: When the tool ended with an error.
group : str, required
Group of raster layers to be classified
GRASS imagery group of raster maps representing feature variables to be used in the machine learning model
Used as: input, group, name
trainingmap : str, optional
Labelled pixels
Raster map with labelled pixels for training
Used as: input, raster, name
trainingpoints : str, optional
Vector map with training samples
Vector points map where each point is used as training sample. Handling of missing values in training data can be choosen later.
Used as: input, vector, name
field : str, optional
Response attribute column
Name of attribute column in trainingpoints table containing response values
Used as: input, dbcolumn, name
output : str, optional
Output Map
Raster layer name to store result from classification or regression model. The name will also used as a perfix if class probabilities or intermediate of cross-validation results are ordered as maps.
Used as: output, raster, name
classifier : str, optional
Classifier
Supervised learning model to use
Allowed values: LogisticRegression, LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis, KNeighborsClassifier, GaussianNB, DecisionTreeClassifier, DecisionTreeRegressor, RandomForestClassifier, RandomForestRegressor, ExtraTreesClassifier, ExtraTreesRegressor, GradientBoostingClassifier, GradientBoostingRegressor, SVC, EarthClassifier, EarthRegressor
Default: RandomForestClassifier
c : float | list[float] | str, optional
Inverse of regularization strength
Inverse of regularization strength (LogisticRegression and SVC)
Default: 1.0
max_features : int | list[int] | str, optional
Number of features available during node splitting; zero uses classifier defaults
Number of features available during node splitting (tree-based classifiers and regressors)
Default: 0
max_depth : int | list[int] | str, optional
Maximum tree depth; zero uses classifier defaults
Maximum tree depth for tree-based method; zero uses classifier defaults (full-growing for Decision trees and Randomforest, 3 for GBM)
Default: 0
min_samples_split : int | list[int] | str, optional
The minimum number of samples required for node splitting
The minimum number of samples required for node splitting in tree-based classifiers
Default: 2
min_samples_leaf : int | list[int] | str, optional
The minimum number of samples required to form a leaf node
The minimum number of samples required to form a leaf node in tree-based classifiers
Default: 1
n_estimators : int | list[int] | str, optional
Number of estimators
Number of estimators (trees) in ensemble tree-based classifiers
Default: 100
learning_rate : float | list[float] | str, optional
learning rate
learning rate (also known as shrinkage) for gradient boosting methods
Default: 0.1
subsample : float | list[float] | str, optional
The fraction of samples to be used for fitting
The fraction of samples to be used for fitting, controls stochastic behaviour of gradient boosting methods
Default: 1.0
max_degree : int | list[int] | str, optional
The maximum degree of terms in forward pass
The maximum degree of terms in forward pass for Py-earth
Default: 1
n_neighbors : int | list[int] | str, optional
Number of neighbors to use
Number of neighbors to use
Default: 5
weights : str | list[str], optional
weight function
Distance weight function for k-nearest neighbours model prediction
Allowed values: uniform, distance
Default: uniform
grid_search : str, optional
Resampling method to use for hyperparameter optimization
Resampling method to use for hyperparameter optimization
Allowed values: cross-validation, holdout
Default: cross-validation
categorymaps : str | list[str], optional
Names of categorical rasters within the imagery group
Names of categorical rasters within the imagery group that will be one-hot encoded. Leave empty if none.
Used as: input, raster, name
cvtype : str, optional
Non-spatial or spatial cross-validation
Perform non-spatial, clumped or clustered k-fold cross-validation
Allowed values: non-spatial, clumped, kmeans
Default: Non-spatial
n_partitions : int, optional
Number of k-means spatial partitions
Number of k-means spatial partitions for k-means clustered cross-validation
Default: 10
group_raster : str, optional
Custom group ids for training samples from GRASS raster
GRASS raster containing group ids for training samples. Samples with the same group id will not be split between training and test cross-validation folds
Used as: input, raster, name
cv : int, optional
Number of cross-validation folds
Default: 1
n_permutations : int, optional
Number of permutations to perform for feature importances
Default: 10
errors_file : str, optional
Save cross-validation global accuracy results to csv
Name for output file
Used as: output, file, name
preds_file : str, optional
Save cross-validation predictions to csv
Name for output file
Used as: output, file, name
fimp_file : str, optional
Save feature importances to csv
Name for output file
Used as: output, file, name
param_file : str, optional
Save hyperparameter search scores to csv
Name for output file
Used as: output, file, name
random_state : int, optional
Seed to use for random state
Default: 1
indexes : int | list[int] | str, optional
Indexes of class probabilities to predict. Default -1 predicts all classes
Default: -1
rowincr : int, optional
Maximum number of raster rows to read/write in single chunk whilst performing prediction
Default: 25
n_jobs : int, optional
Number of cores for multiprocessing, -2 is n_cores-1
Default: -2
save_training : str, optional
Save training data to csv
Name for output file
Used as: output, file, name
load_training : str, optional
Load training data from csv
Name of input file
Used as: input, file, name
save_model : str, optional
Save model to file (for compression use e.g. '.gz' extension)
Name for output file
Used as: output, file, name
load_model : str, optional
Load model from file
Name of input file
Used as: input, file, name
flags : str, optional
Allowed values: t, f, r, s, p, z, m, b, l
t
Perform hyperparameter tuning only
f
Estimate permutation-based feature importances
Estimate feature importance using a permutation-based method
r
Make predictions for cross validation resamples
Produce raster predictions for all cross validation resamples
s
Standardization preprocessing
Standardize feature variables (convert values the get zero mean and unit variance).
p
Output class membership probabilities
A raster layer is created for each class. It is recommended to give a list of particular classes in interest to avoid consumption of large amounts of disk space.
z
Only predict class probabilities
m
Build model only - do not perform prediction
b
Balance training data using class weights
l
Use memory swap
overwrite : bool, optional
Allow output files to overwrite existing files
Default: None
verbose : bool, optional
Verbose module output
Default: None
quiet : bool, optional
Quiet module output
Default: None
superquiet : bool, optional
Very quiet module output
Default: None
DESCRIPTION
r.learn.ml represents a front-end to the scikit learn python package. The module enables scikit-learn classification and regression models to be applied to GRASS GIS rasters that are stored as part of an imagery group group or specified as individual maps in the optional raster parameter. Several commonly used classifiers and regressors are exposed in the GUI and the choice of classifier is set using the classifier parameter. For more details relating to the classifiers, refer to the scikit learn documentation. The following classification and regression methods are available:
- LogisticRegression represents a linear model for classification and is a modification of linear regression, but using the logistic distribution which enables the use of a categorical response variable. If the response raster is coded to 0 and 1, then a binary classification occurs, but the scikit-learn logistic regression can also perform a multiclass classification using a one-versus-rest scheme.
- LinearDiscriminantAnalysis and QuadraticDiscriminantAnalysis are classifiers with linear and quadratic decision surfaces. These classifiers do not take any parameters and are inherently multiclass. They can only be used for classification.
- KNeighborsClassifier classifies samples based on closest distance to a predefined number of training samples. Two hyperparameters are exposed, with n_neighbors governing the number of neighbors to use to decide the prediction label, and weights specifying whether these neighbors should have equal weights or whether they should be inversely weighted by their distance.
- GaussianNB is the Gaussian Naive Bayes algorithm and can be used for classification only. Naive Bayes is a supervised learning algorithm based on applying Bayes theorem with the naive assumption of independence between every pair of features. This classifier does not take any parameters.
- The DecisionTreeClassifier and DecisionTreeRegressor map observations to a response variable using a hierarchy of splits and branches. The terminus of these branches, termed leaves, represent the prediction of the response variable. Decision trees are non-parametric and can model non-linear relationships between a response and predictor variables, and are insensitive the scaling of the predictors.
- The RandomForestsClassifier and RandomForestsRegressor represent ensemble classification and regression tree methods. Random forests overcome some of the disadvantages of single decision trees by constructing an ensemble of uncorrelated trees. Each tree is constructed from a random subsample of the training data and only a random subset of the predictors based on max_features is made available during each node split. Each tree produces a prediction probability and the final classification result is obtained by averaging of the prediction probabilities across all of the trees. The ExtraTreesClassifier is a variant on random forests where during each node split, the splitting rule that is selected is based on the best of a collection of randomly-geneated thresholds that were assigned to the features.
- The GradientBoostingClassifier and GradientBoostingRegressor also represent ensemble tree-based methods. However, in a boosted model the learning processes is additive in a forward step-wise fashion whereby n_estimators are fit during each model step, and each model step is designed to better fit samples that are not currently well predicted by the previous step. This incrementally improves the performance of the entire model ensemble by fitting to the model residuals. Additionally, Microsoft's LGBMClassifier and LGBMRegressor models represent an accelerated version of gradient boosting which can optionally be installed by pip install lightgbm.
- The SVC model is C-Support Vector Classifier. Only a linear kernel is supported because non-linear kernels using scikit learn for typical remote sensing and spatial analysis datasets which consist of large numbers of samples are too slow to be practical. This classifier can still be slow for large datasets that include > 10000 training samples.
- The EarthClassifier and EarthRegressor is a python-based version of Friedman's multivariate adaptive regression splines. This classifier depends on the py-earth package, which optionally can be installed in addition to scikit-learn. Earth represents a non-parametric extension to linear models such as logistic regression which improves model fit by partitioning the data into subregions, with each region being fitted by a separate regression term.
The Classifier parameters tab provides access to the most pertinent parameters that affect the previously described algorithms. The scikit-learn classifier defaults are generally supplied, and some of these parameters can be tuning using a grid-search by inputting multiple parameter settings as a comma-separated list. This tuning can also be accomplished simultaneously with nested cross-validation by also settings the cv option to > 1. The parameters consist of:
- C is the inverse of the regularization strength, which is when a penalty is applied to avoid overfitting. C applies to the LogisticRegression and SVC models.
- n_estimators represents the number of trees in Random Forest model, and the number of trees used in each model step during Gradient Boosting. For random forests, a larger number of trees will never adversely affect accuracy although this is at the expensive of computational performance. In contrast, Gradient boosting will start to overfit if n_estimators is too high, which will reduce model accuracy.
- max_features controls the number of variables that are allowed to be chosen from at each node split in the tree-based models, and can be considered to control the degree of correlation between the trees in ensemble tree methods.
- min_samples_split and min_samples_leaf control the number of samples required to split a node or form a leaf node, respectively.
- The learning_rate and subsample parameters apply only to Gradient Boosting. learning_rate shrinks the contribution of each tree, and subsample is the fraction of randomly selected samples for each tree. A lower learning_rate always improves accuracy in gradient boosting but will require a much larger n_estimators setting which will lower computational performance.
- The main control on accuracy in the Earth classifier consists max_degree which is the maximum degree of terms generated by the forward pass. Settings of max_degree = 1 or 2 offer good accuracy versus computational performance.
In addition to model fitting and prediction, feature selection can be performed using the -f flag. The feature selection method employed is based on Brenning et al. (2012) and consists of a custom permutation-based method that can be applied to all of the classifiers as part of a cross-validation. The method consists of: (1) determining a performance metric on a test partition of the data; (2) permuting each variable and assessing the difference in performance between the original and permutation; (3) repeating step 2 for n_permutations; (4) averaging the results. Steps 1-4 are repeated on each k partition. The feature importance represent the average decrease in performance of each variable when permuted. For binary classifications, the AUC is used as the metric. Multiclass classifications use accuracy, and regressions use R2.
Cross validation can be performed by setting the cv parameters to >
- Cross-validation is performed using stratified kfolds, and multiple global and per-class accuracy measures are produced depending on whether the response variable is binary or multiclass, or the classifier is for regression or classification. The cvtype parameter can also be changed from 'non-spatial' to either 'clumped' or 'kmeans' to perform spatial cross-validation. Clumped spatial cross-validation is used if the training pixels represent polygons, and then cross-validation will be effectively performed on a polygon basis. Kmeans spatial cross-validation will partition the training pixels into n_partitions by kmeans clustering of the pixel coordinates. These partitions will then be used for cross-validation, which should provide more realistic performance measures if the data are spatially correlated. If these partioning schemes are not sufficient then a raster containing the group_ids of the partitions can be supplied using the group_raster option.
Although tree-based classifiers are insensitive to the scaling of the input data, other classifiers such as linear models may not perform optimally if some predictors have variances that are orders of magnitude larger than others. The -s flag adds a standardization preprocessing step to the classification and prediction to reduce this effect. Additionally, most of the classifiers do not perform well if there is a large class imbalance in the training data. Using the -b flag balances the training data by weighting of the minority classes relative to the majority class. This does not apply to the Naive Bayes or LinearDiscriminantAnalysis classifiers.
Non-ordinal, categorical predictors are also not specifically recognized by scikit-learn. Some classifiers are not very sensitive to this (i.e. decision trees) but generally, categorical predictors need to be converted to a suite of binary using onehot encoding (i.e. where each value in a categorical raster is parsed into a separate binary grid). Entering the indices (comma-separated) of the categorical rasters as they are listed in the imagery group as 0...n in the categorymaps option will cause onehot encoding to be performed on the fly during training and prediction. The feature importances are returned as per the original imagery group and represent the sum of the feature importances of the onehot-encoded variables. Note: it is important that the training samples all of the categories in the rasters, otherwise the onehot-encoding will fail when it comes to the prediction.
The module also offers the ability to save and load a classification or regression model (save_model=name[.gz]). Note that the model file size can become quite large; when using a supported filename extensions (incl. '.gz', '.bz2', '.xz' or '.lzma') the model file will be automatically compressed. Saving and loading a model allows a model to be fitted on one imagery group, with the prediction applied to additional imagery groups. This approach is commonly employed in species distribution or landslide susceptibility modelling whereby a classification or regression model is built with one set of predictors (e.g. present-day climatic variables) and then predictions can be performed on other imagery groups containing forecasted climatic variables.
For convenience when performing repeated classifications using different classifiers or parameters, the training data can be saved to a csv file using the save_training option. This data can then be loaded into subsequent classification runs, saving time by avoiding the need to repeatedly query the predictors.
NOTES
r.learn.ml uses the "scikit-learn" machine learning python package along with the "pandas" package. These packages need to be installed within your GRASS GIS Python environment. For Linux users, these packages should be available through the linux package manager. For MS-Windows users using a 64 bit GRASS, the easiest way of installing the packages is by using the precompiled binaries from Christoph Gohlke and by using the OSGeo4W installation method of GRASS, where the python setuptools can also be installed. You can then use 'easy_install pip' to install the pip package manager. Then, you can download the NumPy+MKL and scikit-learn .whl files and install them using 'pip install packagename.whl'. For MS-Windows with a 32 bit GRASS, scikit-learn is available in the OSGeo4W installer.
r.learn.ml is designed to keep system memory requirements relatively low. For this purpose, the rasters are read from the disk row-by-row, using the RasterRow method in PyGRASS. This however does not represent an efficient volume of data to pass to the classifiers, which are mostly multithreaded. Therefore, groups of rows specified by the rowincr parameter are passed to the classifier, and the reclassified image is reconstructed and written row-by-row back to the disk. rowincr=25 should be reasonable for most systems with 4-8 GB of ram. The row-by-row access however results in slow performance when sampling the imagery group to build the training data set when providing a raster as the trainingmap. Instead, the default behaviour is to read each predictor into memory at a time. If this still exceeds the system memory then the -l flag can be set to write each predictor to a numpy memmap file, and classification/regression can then be performed on rasters of any size irrespective of the available memory.
Many of the classifiers involve a random process which can causes a small amount of variation in the classification results, out-of-bag error, and feature importances. To enable reproducible results, a seed is supplied to the classifier. This can be changed using the randst parameter.
EXAMPLE
Here we are going to use the GRASS GIS sample North Carolina data set as a basis to perform a landsat classification. We are going to classify a Landsat 7 scene from 2000, using training information from an older (1996) land cover dataset.
Landsat 7 (2000) bands 7,4,2 color composite example:
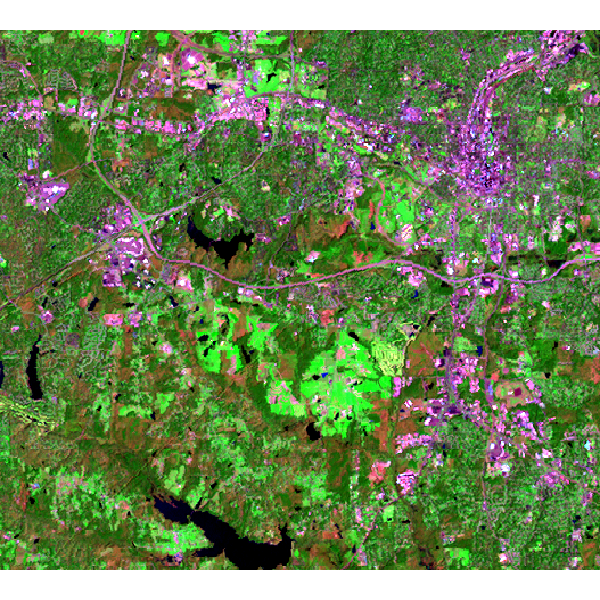
Note that this example must be run in the "landsat" mapset of the North Carolina sample data set location.
First, we are going to generate some training pixels from an older (1996) land cover classification:
g.region raster=landclass96 -p
r.random input=landclass96 npoints=1000 raster=landclass96_roi
Next, we create the imagery group with all Landsat 7 (2000) bands:
i.group group=lsat7_2000 input=lsat7_2002_10,lsat7_2002_20,lsat7_2002_30,lsat7_2002_40,lsat7_2002_50,lsat7_2002_61,lsat7_2002_62,lsat7_2002_70,lsat7_2002_80
Then we can use these training pixels to perform a classification on the more recently obtained landsat 7 image:
r.learn.ml group=lsat7_2000 trainingmap=landclass96_roi output=rf_classification \
classifier=RandomForestClassifier n_estimators=500
# copy category labels from landclass training map to result
r.category rf_classification raster=landclass96_roi
# copy color scheme from landclass training map to result
r.colors rf_classification raster=landclass96_roi
r.category rf_classification
Random forest classification result:

ACKNOWLEDGEMENTS
Thanks for Paulo van Breugel and Vaclav Petras for testing.
REFERENCES
Brenning, A. 2012. Spatial cross-validation and bootstrap for the assessment of prediction rules in remote sensing: the R package 'sperrorest'. 2012 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 23-27 July 2012, p. 5372-5375.
Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
AUTHOR
Steven Pawley
SOURCE CODE
Available at: r.learn.ml source code
(history)
Latest change: Wednesday Mar 11 08:17:30 2026 in commit 2a14bbb