r.learn.predict
Apply a fitted scikit-learn estimator to rasters in a GRASS GIS imagery group.
r.learn.predict [-pz] group=name load_model=name output=name [chunksize=integer] [--overwrite] [--verbose] [--quiet] [--qq] [--ui]
Example:
r.learn.predict group=name load_model=name output=name
grass.tools.Tools.r_learn_predict(group, load_model, output, chunksize=100000, flags=None, overwrite=None, verbose=None, quiet=None, superquiet=None)
Example:
tools = Tools()
tools.r_learn_predict(group="name", load_model="name", output="name")
This grass.tools API is experimental in version 8.5 and expected to be stable in version 8.6.
grass.script.run_command("r.learn.predict", group, load_model, output, chunksize=100000, flags=None, overwrite=None, verbose=None, quiet=None, superquiet=None)
Example:
gs.run_command("r.learn.predict", group="name", load_model="name", output="name")
Parameters
group=name [required]
Group of raster layers used for prediction
GRASS imagery group of raster maps representing feature variables to be used in the machine learning model
load_model=name [required]
Load model from file
File representing pickled scikit-learn estimator model
output=name [required]
Output Map
Raster layer name to store result from classification or regression model. The name will also used as a perfix if class probabilities or intermediate of cross-validation results are ordered as maps.
chunksize=integer
Number of pixels to pass to the prediction method
Number of pixels to pass to the prediction method. GRASS GIS reads raster by-row so chunksize is rounded down based on the number of columns
Default: 100000
-p
Output class membership probabilities
A raster layer is created for each class. For the case of a binary classification, only the positive (maximum) class is output
-z
Only predict class probabilities
--overwrite
Allow output files to overwrite existing files
--help
Print usage summary
--verbose
Verbose module output
--quiet
Quiet module output
--qq
Very quiet module output
--ui
Force launching GUI dialog
group : str, required
Group of raster layers used for prediction
GRASS imagery group of raster maps representing feature variables to be used in the machine learning model
Used as: input, group, name
load_model : str | io.StringIO, required
Load model from file
File representing pickled scikit-learn estimator model
Used as: input, file, name
output : str | type(np.ndarray) | type(np.array) | type(gs.array.array), required
Output Map
Raster layer name to store result from classification or regression model. The name will also used as a perfix if class probabilities or intermediate of cross-validation results are ordered as maps.
Used as: output, raster, name
chunksize : int, optional
Number of pixels to pass to the prediction method
Number of pixels to pass to the prediction method. GRASS GIS reads raster by-row so chunksize is rounded down based on the number of columns
Default: 100000
flags : str, optional
Allowed values: p, z
p
Output class membership probabilities
A raster layer is created for each class. For the case of a binary classification, only the positive (maximum) class is output
z
Only predict class probabilities
overwrite : bool, optional
Allow output files to overwrite existing files
Default: None
verbose : bool, optional
Verbose module output
Default: None
quiet : bool, optional
Quiet module output
Default: None
superquiet : bool, optional
Very quiet module output
Default: None
Returns:
result : grass.tools.support.ToolResult | np.ndarray | tuple[np.ndarray] | None
If the tool produces text as standard output, a ToolResult object will be returned. Otherwise, None will be returned. If an array type (e.g., np.ndarray) is used for one of the raster outputs, the result will be an array and will have the shape corresponding to the computational region. If an array type is used for more than one raster output, the result will be a tuple of arrays.
Raises:
grass.tools.ToolError: When the tool ended with an error.
group : str, required
Group of raster layers used for prediction
GRASS imagery group of raster maps representing feature variables to be used in the machine learning model
Used as: input, group, name
load_model : str, required
Load model from file
File representing pickled scikit-learn estimator model
Used as: input, file, name
output : str, required
Output Map
Raster layer name to store result from classification or regression model. The name will also used as a perfix if class probabilities or intermediate of cross-validation results are ordered as maps.
Used as: output, raster, name
chunksize : int, optional
Number of pixels to pass to the prediction method
Number of pixels to pass to the prediction method. GRASS GIS reads raster by-row so chunksize is rounded down based on the number of columns
Default: 100000
flags : str, optional
Allowed values: p, z
p
Output class membership probabilities
A raster layer is created for each class. For the case of a binary classification, only the positive (maximum) class is output
z
Only predict class probabilities
overwrite : bool, optional
Allow output files to overwrite existing files
Default: None
verbose : bool, optional
Verbose module output
Default: None
quiet : bool, optional
Quiet module output
Default: None
superquiet : bool, optional
Very quiet module output
Default: None
DESCRIPTION
r.learn.predict performs the prediction phase of a machine learning workflow. The user is required to load a prefitted scikit-learn estimator using the load_model parameter, which can be developed using the r.learn.train module, or can represent any fitted scikit-learn compatible estimator that is pickled to a file. The GRASS GIS imagery group to apply the model is set using the group parameter.
NOTES
r.learn.predict is designed to keep system memory requirements relatively low. For this purpose, the rasters are read from the disk row-by-row, using the RasterRow method in PyGRASS. This however does not represent an efficient volume of data to pass to the classifiers, which are mostly multithreaded. Instead, groups of rows as passed to the estimator. The chunksize parameter represents the maximum memory size (in MB) for each of these blocks of data. Note that the module will consume more memory than this, especially if the estimator model was trained using multiple cores.
EXAMPLE
Here we are going to use the GRASS GIS sample North Carolina data set as a basis to perform a landsat classification. We are going to classify a Landsat 7 scene from 2000, using training information from an older (1996) land cover dataset.
Landsat 7 (2000) bands 7,4,2 color composite example:
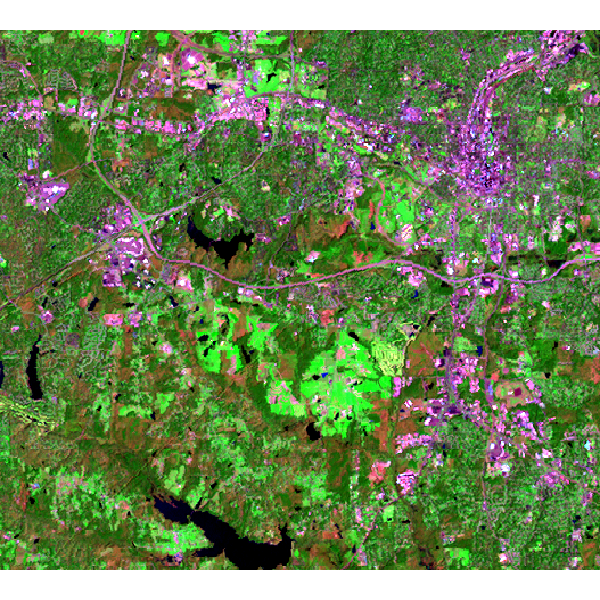
Note that this example must be run in the "landsat" mapset of the North Carolina sample data set location.
First, we are going to generate some training pixels from an older (1996) land cover classification:
g.region raster=landclass96 -p
r.random -s input=landclass96 npoints=1000 raster=training_pixels
Then we can use these training pixels to perform a classification on the more recently obtained landsat 7 image:
# train a random forest classification model using r.learn.train
r.learn.train group=lsat7_2000 training_map=training_pixels \
model_name=RandomForestClassifier n_estimators=500 save_model=rf_model.gz
# perform prediction using r.learn.predict
r.learn.predict group=lsat7_2000 load_model=rf_model.gz output=rf_classification
# check raster categories - they are automatically applied to the classification output
r.category rf_classification
# copy color scheme from landclass training map to result
r.colors rf_classification raster=training_pixels
Random forest classification result:

SEE ALSO
r.learn.ml2 (overview), r.learn.train
REFERENCES
Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
AUTHOR
Steven Pawley
SOURCE CODE
Available at: r.learn.predict source code
(history)
Latest change: Sunday Jul 19 12:31:18 2026 in commit 907fa8d